運用と監視を通してアプリケーションをより良い方向へ成長させる
はじめに
この記事では弊社が開発したアプリケーションを日々どのように運用しているのかご紹介したいと思います。この記事を読んでくださる方には様々な方がいらっしゃると思いますが、エンジニア以外の方にも運用と監視について目を向ける機会になればと思います。
運用と監視について
運用と監視は互いに補完しあうものだと思っています。運用だけでは作りっぱなしのシステムとなってしまいますし、監視だけ行っても適切なフィードバックを行わなければ測定しているだけであり何も進展はありません。システム構築を行う際、制作するシステムの種類に問わず監視設定を行う事は多いかと思います。その際に運用にフィードバックする方法を検討しないと監視する事が目的になってしまいます。運用と監視は目的ではなくアプリケーションをより良い方向へ成長させるための手段だと思います。
運用監視のライフサイクル
弊社で実際にあったECサイトでの障害を例として運用監視のライフサイクルをご紹介したいと思います。以下で記述するサイクルを実施する事によりアプリケーションを成長させることができます。
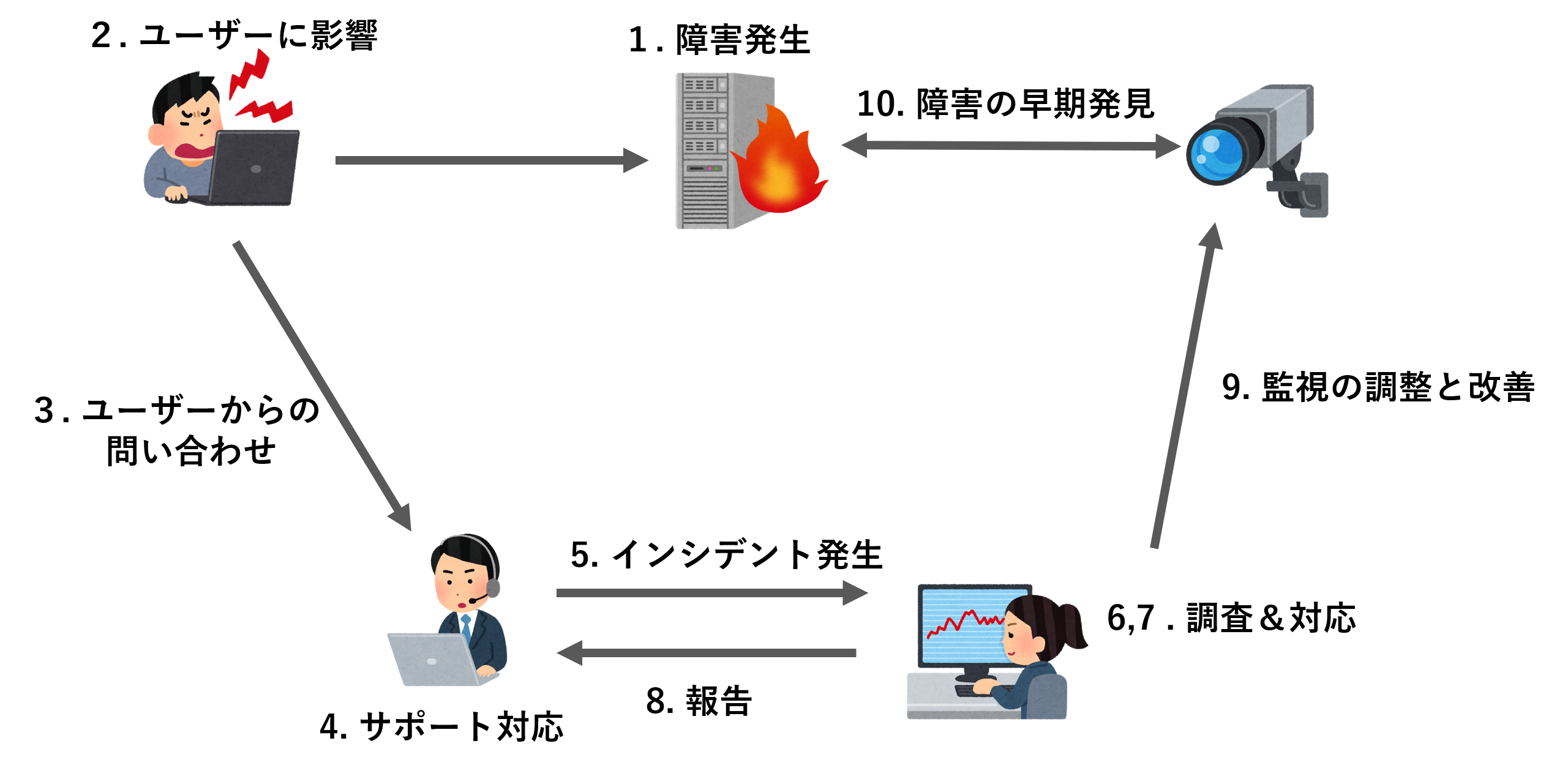
- 障害が発生する
- システムに何かしらの異常が発生します
- ページが見られない、商品が購入できない、予期せぬ箇所でエラーが出る等々…
- システムに何かしらの異常が発生します
- エンドユーザーが障害に直面する
- 発生した障害に一般のユーザーに影響が及んでおり、実施したい操作を正常に行えなくなる
- エラーページが表示される
- 購入が完了しない
- 発生した障害に一般のユーザーに影響が及んでおり、実施したい操作を正常に行えなくなる
- サポートセンターに問い合わせが発生する
- サポートセンターにユーザーから同一の問い合わせが発生する
- 障害の規模によってはサポートセンターがパンクする
- サポートセンターが運用マニュアルに基づいて対応を行う
- 過去に経験したのと同様のケースであればこのタイミングで解決することもできるが、実際には対応できないケースが多い
- システム運用会社に問い合わせが発生する
- 弊社ではBacklogを利用しているため、Backlogから起票が行われる
- 緊急性が高い場合は電話がかかってくる事もある
- 開発会社が障害の原因調査する
- 大規模で緊急性が高い障害であればあるほど、調査に時間がかかる場合が多い、これは監視対象やアプリケーションにも依存するが、それよりも焦りなどの調査する人間の心理的影響が大きい
- 障害の調査に応じて対応する
- 範囲&影響の特定しやすさはシステムから発せられる情報量の多さと質に影響する
- 対応時にミスが連鎖する事がある。通常のオペレーションとは異なるため、データ操作誤りや検証していないようなリカバリ操作等々…
- 障害の報告を行う
- 監視の質が良いと、正確で丁寧な報告が迅速にできる
- 障害の内容と対応方法をもとに監視の調整を行う
- 監視項目や条件の見直し
- 対象メトリックの追加
- 閾値の調整
- アプリケーションを改善するための知見が得られる
- 発生した原因や対処内容から今後、同様の現象が発生しても対処ができるようになるのでアプリケーションの成長に繋がる 今まで行ってきた一例の一部を列挙すると以下のような事を実施している
- 連携先システムへAPI連携している場合のリトライ処理
- サイトのレスポンスタイム測定
- 低下時だけでなく、改善したタイミングでも通知を行う事が大事。長期に渡るレスポンス低下状態と区別する必要がある
- 長期間でレスポンスタイミングが低下している場合は何か障害が発生する予兆である場合が多い
- CDNが障害を起こした際にオリジンを見るようにフォールバックする
- Azure Storage Queueの監視
- Azure FunctionのQueueTriggerが発火しない場合があったため長期間Dequeueされていない物がないかチェック
- Azure Function のTimerTriggerが未発火だった場合の対処
- 日次などのバッチ処理も毎次実行させるように変更。実行済みチェックなどはStorageやFileなどでチェックする
- 発生した原因や対処内容から今後、同様の現象が発生しても対処ができるようになるのでアプリケーションの成長に繋がる 今まで行ってきた一例の一部を列挙すると以下のような事を実施している
- 監視項目や条件の見直し
障害から学ぶ
障害が発生した時に運用監視ルールを見直すことによって、障害の早期発見に繋がっていきます。顧客発生で発見していた障害が、監視の通知を通して自己発見&自己解決できるようになっていくはずです。
通知について
障害の通知は監視からの内容が明確に解るものであり、かつ適切な量が届けられることが好ましいです。弊社では初期段階ではメールでの通知を行っていましたが。現在はSlackによる通知を行っています。
- メールは埋もれたり見ない傾向が強い
- 障害発生時に数百件送られてくることもある
- Slackの場合はWebhookで作成すればよいため作りやすかった
- チャンネルごとにグルーピングできるためテナントごとに管理しやすい
- Slackへの内容をカスタマイズしていくことも重要
- ごみアラートの削除
- 一年間くらい放置して問題ないアラートは消す
- 定期的に発生したり、所定の操作を実施すると毎回発生する例外などがある
- ごみアラートの削除
- 通知の内容を障害時に特定しやすいものになるように心がける(5W1Hを意識すると良い)
- Who : どのアプリケーションで発生したか
- When : 発生時間(UTCやJST)
- Where : メソッド名やFunction名など場所が特定できる内容
- What : 何が発生したのか。Exceptionの種類やTraceLogの場合は具体的な内容
- Why : どのような原因で発生しているか具体的にnullであるはずの物がnullだったり想定外のデータをlogに残るようにする
- How:どうやって発生したのか。ユーザー操作が絡むような場合はURLなどを記載する
結果
システムの運用監視ライフサイクルを日々、循環させていくと様々な結果が出ました。ライフサイクルを進めていくと下図のような状態となり、様々なメリットが発生します。また、少なからず今後の課題も発生しました。
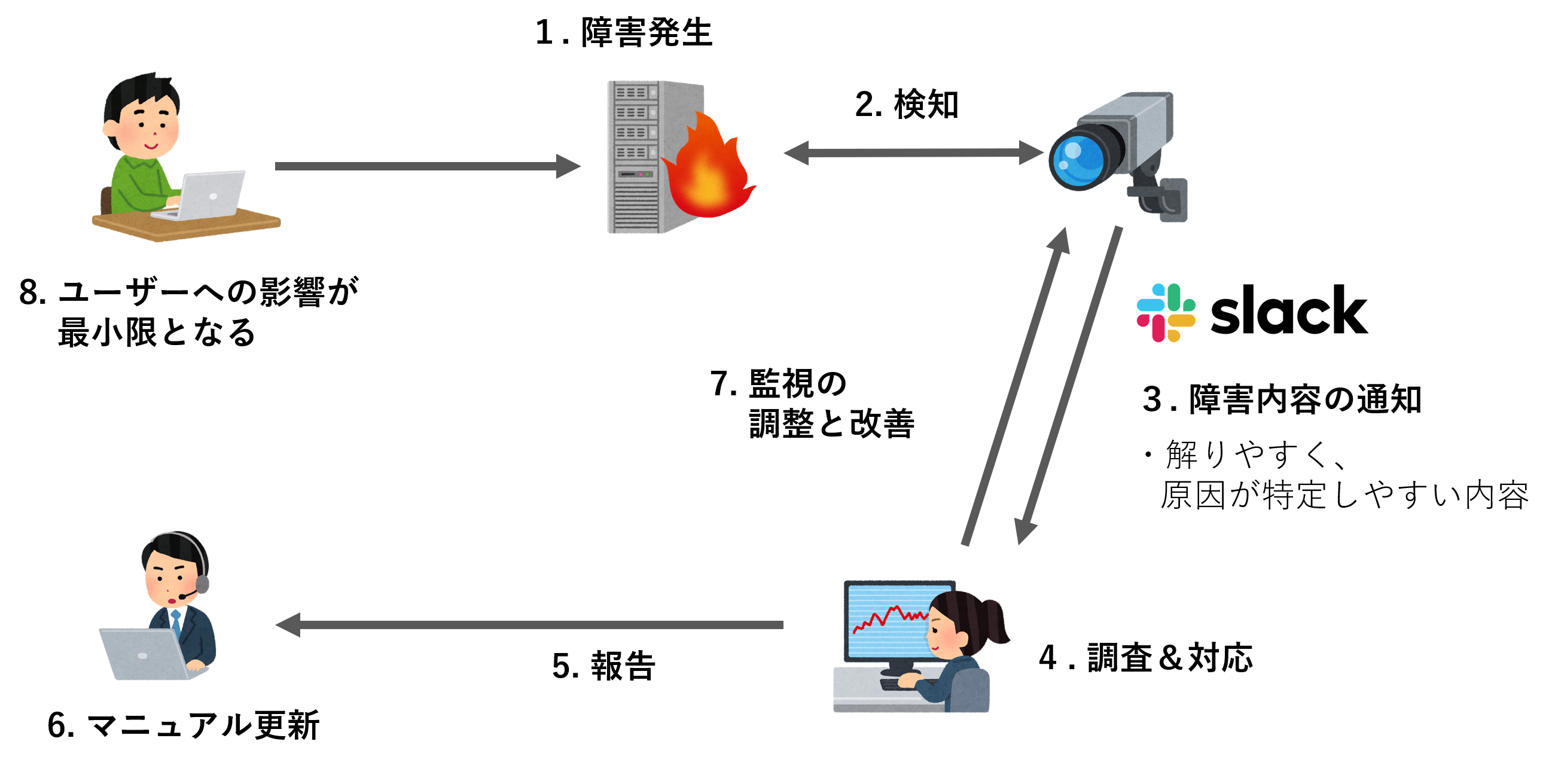
システムと組織の成長に繋がった
当初はシステムの障害に自分たちで気が付くこともできず、顧客からのインシデント発生から認知していた段階から、システム運用者自らが発見し、自発的に修正していく事が可能になってきました。
1つのプロジェクトから生まれた障害例と対応方法を共有する事で会社全体のノウハウ蓄積と品質向上に繋がってきています。
浮き彫りになった課題
一方で新たな課題も生まれています。以下のような課題は今後改善の余地があり、改善に取り組んでいければと思います。
- 監視システムをプロジェクト単位で作成している
- 監視の粒度や品質がプロジェクトごとにバラつきがあるので統一したい
- 障害発生時の対応方法が曖昧
- 気が付いた人が気が付いたタイミングで直している傾向があるので、一度体制を考えた方がよいのかもしれない
お問い合わせはこちらから
問い合わせる

